在Vaswani等人发表的开创性论文"Attention is All You Need"中,研究者引入了用于机器翻译任务的Transformer架构。该模型采用监督学习方式训练,训练数据由输入序列X和目标输出序列Y组成,这些序列对应两种不同语言中的对照句子。在推理阶段,模型以自回归生成方式运行:
ŷ₀ = Transformer(X, SOS)ŷ₁ = Transformer(X, SOS, ŷ₀)ŷ₂ = Transformer(X, SOS, ŷ₀, ŷ₁)...ŷₙ = Transformer(X, SOS, ŷ₀, ŷ₁, ..., ŷₙ₋₁) = EOS
该过程生成与输入序列X对应的输出序列Y = [SOS, ŷ₀, ..., ŷₙ](即翻译结果),其中SOS和EOS分别代表特殊标记"序列起始"和"序列结束"。在后续研究中,Transformer模型已成功扩展到多种模态和任务领域。毫无疑问,Transformer已成为处理序列数据的最先进模型架构。
时间序列分析广泛应用于统计学、信号处理、计量经济学、控制工程以及所有涉及时间维度测量的应用科学与工程领域。时间序列预测是利用时间序列模型基于先前观测值预测未来值的技术。预测问题可以转化为序列到序列(Seq2Seq)模型任务,并采用上述自回归生成推理方式。因此将Transformer技术应用于时间序列预测具有重要研究价值。
研究者已提出多种针对时间序列预测的Transformer适配方案,如LogSparse Transformer、MTS Transformer、Informer和ContiFormer(论文引用文献[1])。这些研究解决了时间序列预测中的各种挑战,包括变化的采样率和长期依赖性建模等问题。然而将标准Transformer(Vaswani等人提出的原始架构)适配于连续数据序列的最小化变更方案尚未明确定义。鉴于标准Transformer最初设计用于处理离散输入输出(标记),无法直接应用于连续数据,必须进行适当调整。先前研究中提出的较为复杂的适配方案引发了一个问题:这些方案尚未与任何基础的"时间序列Transformer基线"进行比较。此外Zeng等人(论文引用[7])的实验研究表明,"令人惊讶的简单"单层线性回归模型在多项基准测试中优于当前最先进的时间序列Transformer模型,这进一步证明了定义一个简单时间序列Transformer基线——即极简时间序列Transformer的必要性。
我们先参考一个简单的的Seq2SeqTransformer类,该类以流行的PyTorch框架中的torch.nn.Transformer类作为核心构建模块。
class Seq2SeqTransformer(nn.Module):
# Constructor
def __init__(
self,
num_tokens,
d_model,
nhead,
num_encoder_layers,
num_decoder_layers,
dim_feedforward,
dropout_p,
layer_norm_eps,
padding_idx = None
):
super().__init__()
self.d_model = d_model
self.padding_idx = padding_idx
if padding_idx != None:
# Token embedding layer - this takes care of converting integer to vectors
self.embedding = nn.Embedding(num_tokens+1, d_model, padding_idx = self.padding_idx)
else:
# Token embedding layer - this takes care of converting integer to vectors
self.embedding = nn.Embedding(num_tokens, d_model)
# Token "unembedding" to one-hot token vector
self.unembedding = nn.Linear(d_model, num_tokens)
# Positional encoding
self.positional_encoder = PositionalEncoding(d_model=d_model, dropout=dropout_p)
# nn.Transformer that does the magic
self.transformer = nn.Transformer(
d_model = d_model,
nhead = nhead,
num_encoder_layers = num_encoder_layers,
num_decoder_layers = num_decoder_layers,
dim_feedforward = dim_feedforward,
dropout = dropout_p,
layer_norm_eps = layer_norm_eps,
norm_first = True
)
def forward(
self,
src,
tgt,
tgt_mask = None,
src_key_padding_mask = None,
tgt_key_padding_mask = None
):
# Note: src & tgt default size is (seq_length, batch_num, feat_dim)
# Token embedding
src = self.embedding(src) * math.sqrt(self.d_model)
tgt = self.embedding(tgt) * math.sqrt(self.d_model)
# Positional encoding - this is sensitive that data _must_ be seq len x batch num x feat dim
# Inference often misses the batch num
if src.dim() == 2: # seq len x feat dim
src = torch.unsqueeze(src,1)
src = self.positional_encoder(src)
if tgt.dim() == 2: # seq len x feat dim
tgt = torch.unsqueeze(tgt,1)
tgt = self.positional_encoder(tgt)
# Transformer output
out = self.transformer(src, tgt, tgt_mask=tgt_mask, src_key_padding_mask = src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=src_key_padding_mask)
out = self.unembedding(out)
return out
模型的主要处理流程包含三个关键步骤:1) 利用PyTorch torch.nn.Embedding类对源序列和目标序列进行嵌入,该类将标记ID(整数值)映射至独热编码向量,再映射至嵌入向量空间;2) 使用遵循原始"Attention is All You Need"论文设计的位置编码器实现位置信息编码;3) 通过线性"反嵌入"层将Transformer输出转换为类别概率分布。值得注意的是,PyTorch交叉熵损失函数的实现已包含softmax非线性激活,因此在forward函数中无需显式添加。PyTorch Transformer类负责处理未来输出的掩码和填充键掩码,相关掩码构造函数在参考代码中已提供。一个常见且容易引起混淆的要求是:源变量和目标变量必须保持三维结构:序列长度 × 批次大小 × 特征向量维度。在类实现内部,包含了一些处理数据形状的辅助步骤,这些步骤通常是编程错误的常见来源。
对处理离散标记的Seq2SeqTransformer进行时间序列适配的最小化修改是:将"整数到向量"的嵌入层(torch.nn.Embedding)替换为能够将连续值向量转换为模型维度向量的层——即"向量到向量"的映射层。神经网络设计中常用的技巧是使用线性层替代嵌入层。这一修改可通过对原始代码进行简单调整实现。原始嵌入代码:
# Token embedding layer - this takes care of converting integer to vectors
self.embedding = nn.Embedding(num_tokens, d_model)
# Token "unembedding" to one-hot token vector
self.unembedding = nn.Linear(d_model, num_tokens)
# Positional encoding
self.positional_encoder = PositionalEncoding(d_model=d_model, dropout=dropout_p)
替换为:
# For continuous embedding & unembedding
self.embedding = nn.Linear(d_input, d_model)
self.unembedding = nn.Linear(d_model, d_input)
在连续值处理场景中,嵌入层将d_input维的样本映射至d_model维的模型向量空间。而在反嵌入步骤中,则执行逆向转换操作。
在时间序列预测任务中,Transformer模型面临三个潜在挑战:
序列长度可能非常长,从数千到数万个样本不等;
时间上相邻的样本通常呈现高度相关性;
可用于训练的数据量可能有限。
针对这些挑战的直接解决方案往往相互冲突。长序列需要高维度模型以为位置信息提供充足的"表示空间";有限的训练数据使大型模型难以有效训练,容易导致过拟合;相邻样本间的强相关性又使得小型模型成为可能选择,因为每个新样本提供的新信息增量可能微乎其微。为满足这些相互冲突的需求,需要采用特殊技术策略。
在现有文献中,研究者尤其关注长序列处理问题。例如对序列进行对数稀疏采样,使位置编码呈对数特性,从而减少对高维模型的需求。Wav2vec 2.0作为音频特征提取的最先进骨干网络,通过首先应用卷积过滤器,然后使用最近邻乘积量化器,将长音频序列压缩为更紧凑的表示形式——即"音频标记"。
面对上述挑战,什么是最简洁的解决方案?在PoTS-Transformer中,保持模型尺寸较小以避免过拟合风险。同时,位置编码在更高维空间中进行,使其能够有效处理长序列数据。具体实现是通过将位置编码器封装在两个线性层之间:第一个线性层执行位置编码扩展,第二个线性层在编码步骤后执行逆向位置压缩:
.init()
# Positional encoding expansion
self.pos_expansion = nn.Linear(d_model, pos_expansion_dim)
self.pos_unexpansion = nn.Linear(pos_expansion_dim, d_model)
.forward()
src = self.pos_expansion(src)
src = self.positional_encoder(src)
src = self.pos_unexpansion(src)
在PoTS-Transformer模型中,使用8维向量执行核心Transformer计算,但通过128维向量空间进行位置编码,这使得模型可学习参数数量从1,433增加至3,473(增加2.4倍)。作为对比,若将MiTS-Transformer的模型维度从8直接增加到128,其参数数量将从1,289激增至204,689(增加158倍)。两者之间的差距接近两个数量级,充分说明了PoTS-Transformer架构的参数效率。
所有Transformer模型均采用标准PyTorch Adam优化器(torch.optim.Adam)进行训练,初始学习率设为0.023。训练过程中使用多步学习率调度器,当训练轮次达到预设里程碑时,按gamma因子衰减各参数组的学习率。gamma固定为0.1,各实验场景的里程碑点经手动优化确定,并记录目标损失值以便复现所有实验结果。
值得注意的是,使用固定学习率0.023且不进行学习率调度,训练2000轮同样能获得类似效果。在我们的实验中,即使训练最大规模的模型,在不依赖GPU的标准笔记本电脑上也仅需几分钟计算时间。
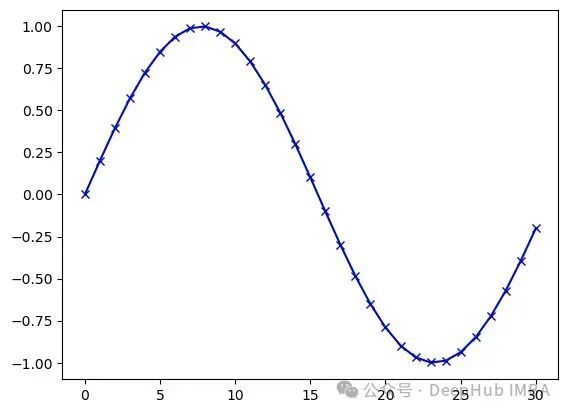
实验中使用的Seq2Seq数据通过采样正弦函数生成:
y(t) = sin 2πf t
其中f表示正弦波频率,t定义时间采样点。对于离散信号处理,将频率定义为每采样点数的波形周期数更为便捷。例如,f = 1/31表示每31个样本完成1个完整波形。
def gen_sinusoidal(seq_len_, disc_freq_):
#seq_len: Anything
#disc_freq: waves per signal lenght, e.g., 2/seq_len
t = np.arange(seq_len_)
y = np.sin(2*np.pi*disc_freq_*t)
return t,y
sin_len = 31
max_f = 1/sin_len # To make sure no sampling effects occur too much
t,y = gen_sinusoidal(sin_len, max_f)
print(f'Sequence length is {sin_len} and frequency {max_f:.4f} (meaning {max_f*sin_len:.4f} waves per seg) ')
plt.plot(t,y,'b-')
plt.plot(t,y,'bx')
#plt.savefig('sin_example_4.png', bbox_inches='tight')
plt.show()
当频率增加时,开始出现采样误差现象,但在本研究场景中,这一影响可以忽略(如下图所示)。
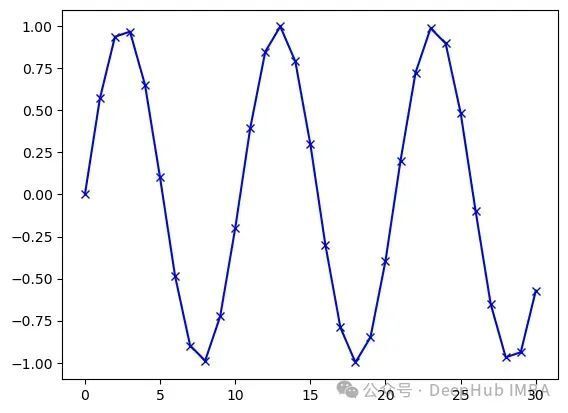
数据类型
实验中构造了三种类型的数据:
类型1:单一序列(f = 1/L的正弦波)
类型2:固定数量序列集合(例如,f = 0/L, 1/L, 2/L, 3/L)
类型3:任意频率序列(f ∈ U(0, fmax))
其中U()表示均匀随机分布。类型1用于模型基本功能验证;类型2代表仅包含有限不同序列的简单场景;类型3是最具挑战性的情况,因为频率接近的两个正弦波之间的差异可能极其微小。在所有实验中,信号长度统一设置为31,分割为19个输入(源)样本X和12个输出(目标)样本Y。
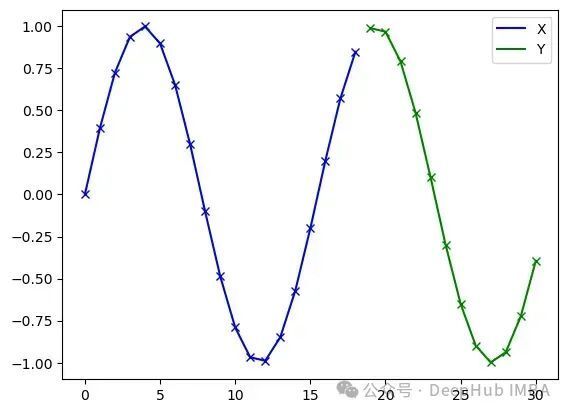
序列的源(X)和目标(Y)部分示意图
基本健全性验证采用长度L = 31、频率f = 1/31的单一正弦波进行。该信号在训练集和测试集中各重复100次,模拟标准训练过程。
MiTS-Transformer — 模型在200轮训练后收敛,采用固定学习率0.023,最终达到MSE误差0.23。
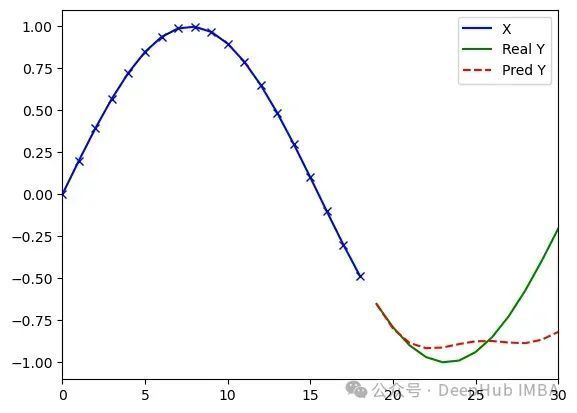
训练100轮后的预测结果示例
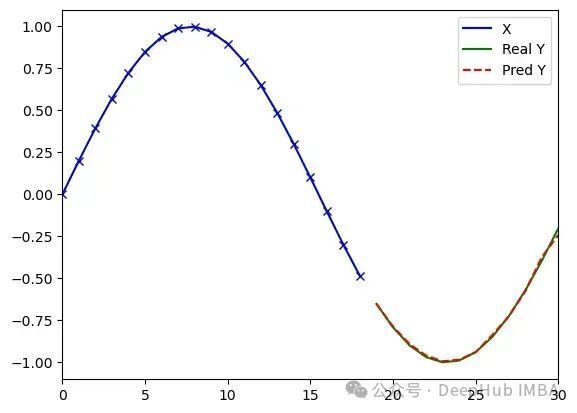
训练200轮后的预测结果示例
MiTS-Transformer — 实验结果如下图所示。单一序列和多序列(四个)场景下的预测准确度几乎没有明显差异。
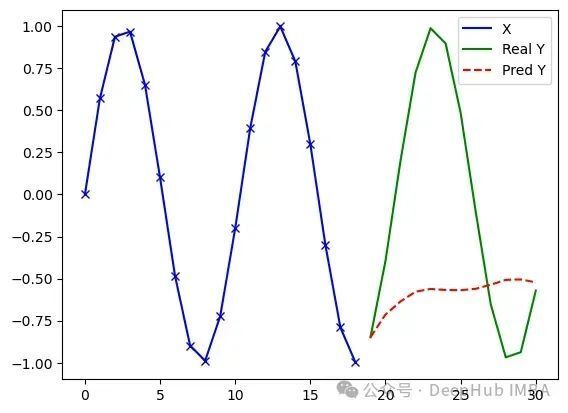
训练100轮,损失值0.056,误差7.30
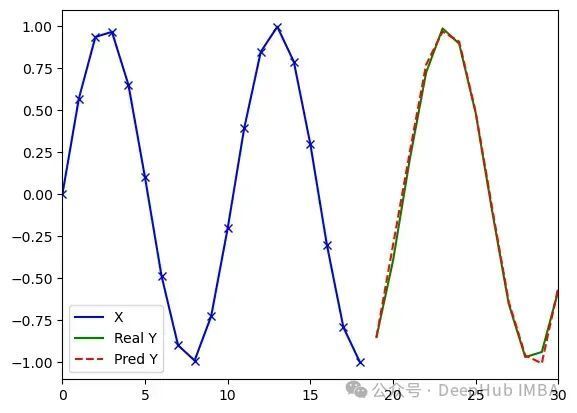
训练600轮,损失值0.012,误差0.61
MiTS-Transformer — 以下展示了三次独立运行的结果及可视化示例,这些运行采用相同的训练和测试数据集。
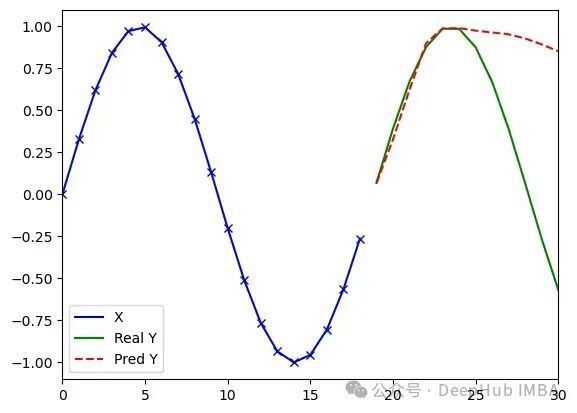
.jpg)
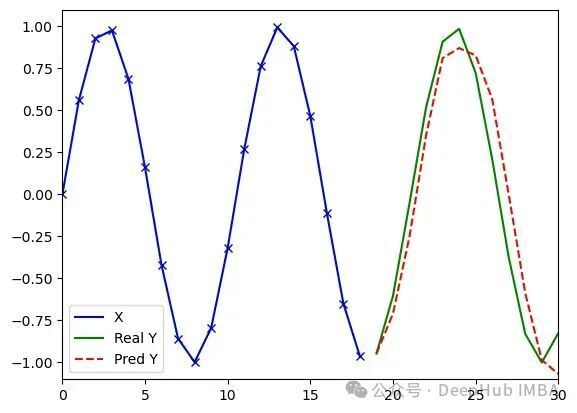
MiTS-Transformer处理任意序列(类型3)的实验结果(d_model=8, dim_feedforward=8, 1289参数)。测试数据由频率范围在(0/31, 3/31)之间的随机正弦波序列组成。运行1(左):损失值0.018,误差4.32;运行2(中):损失值0.019,误差3.28;运行3(右):损失值0.021,误差3.37。训练和测试数据集相同,模型以固定学习率训练2000轮。结果表明不同随机初始化对训练过程存在影响。
实验结果验证了极简时间序列Transformer能够有效处理序列中包含任意微小变化的数据。结果证实了模型具有一定的插值能力,因为许多测试序列并未出现在训练数据中。但是在任意序列场景下的预测性能比固定序列类型1和类型2的结果差了约一个数量级。MiTS-Transformer的学习能力可通过增加模型维度(d_model)有效提升。以下是模型维度分别设置为16和32时的实验结果。
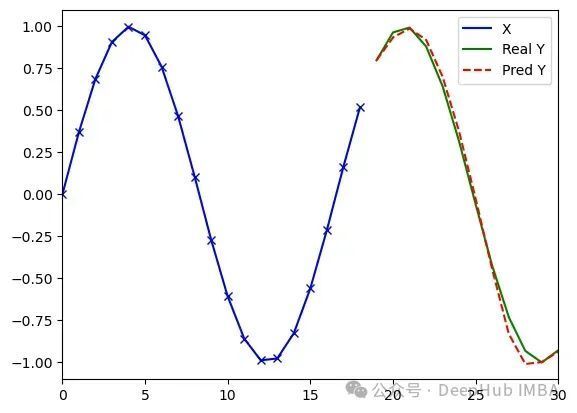
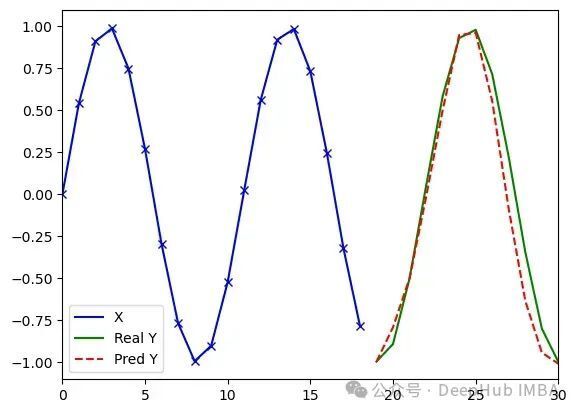
MiTS-Transformer处理任意序列(类型3)的实验结果(d_model=16, dim_feedforward=8, 4097参数)。运行1:损失值0.008,误差3.16;运行2:损失值0.010,误差2.66
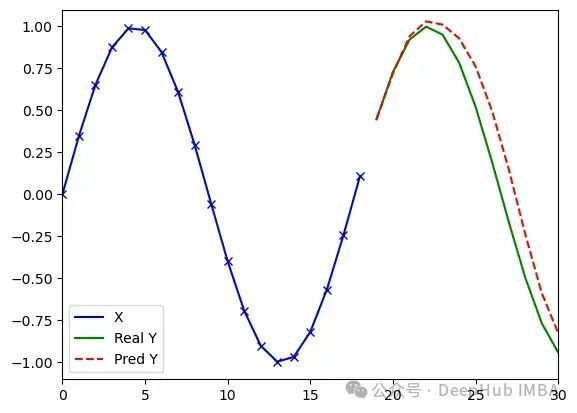
运行3:损失值0.010,误差2.29
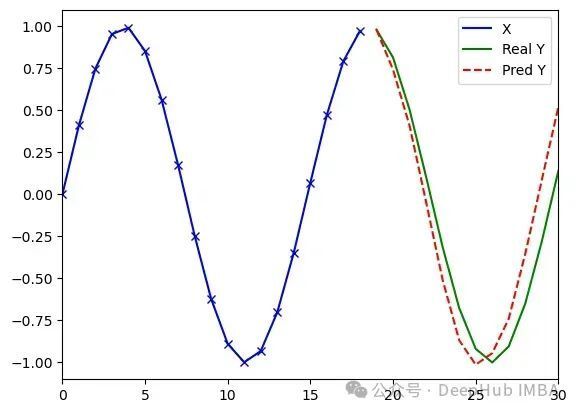
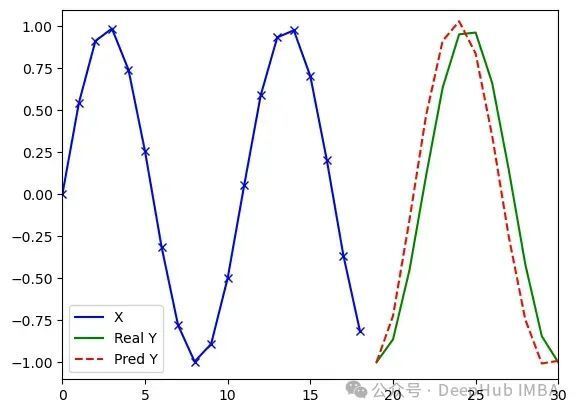
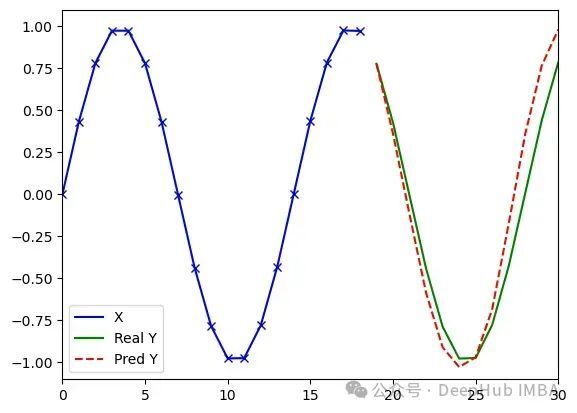
MiTS-Transformer处理任意序列(类型3)的实验结果(d_model=32, dim_feedforward=8, 14321参数)。运行1:损失值0.004,误差1.46;运行2:损失值0.011,误差3.02;运行3:损失值0.006,误差2.76
实验表明,维度为16的模型在各项指标上系统性地优于维度为8的模型,而维度为32的模型则开始出现对训练数据的过度拟合现象。三种规模模型的可学习参数总量分别为1289、4097和14321。
PoTS-Transformer — 这组实验使用位置编码扩展维度64,总计2,385个可学习参数。以下结果显示,PoTS-Transformer在预测性能上系统性地优于MiTS-Transformer。
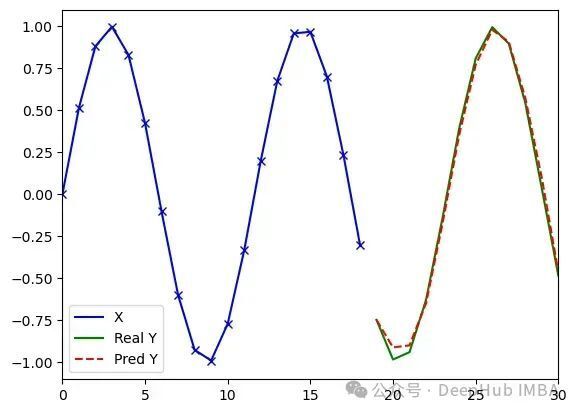
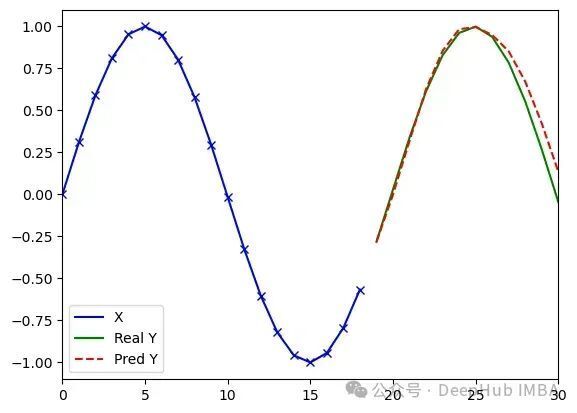
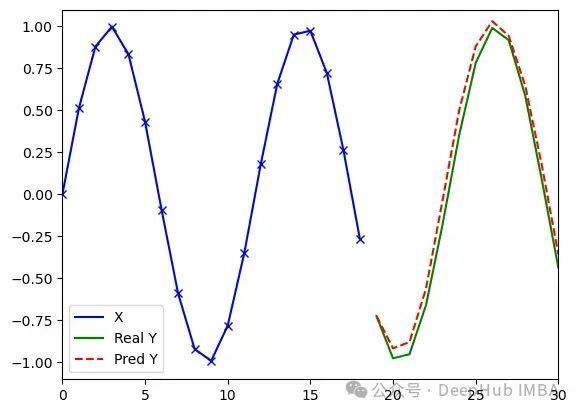
PoTS-Transformer处理任意序列(类型3)的实验结果(d_model=8, dim_feedforward=8, pos_expansion_dim=64, 2,385参数)。运行1:损失值0.004,误差1.31;运行2:损失值0.006,误差1.49;运行3:损失值0.005,误差1.45
最小化适配方案是将标记嵌入层替换为线性映射层。这一技术在本文提出的极简时间序列Transformer(MiTS-Transformer)中得到实现,该模型能够有效学习正弦波序列模式。MiTS-Transformer的学习能力可通过调整模型维度参数灵活配置。然而,简单增加模型维度会导致可学习参数数量急剧增长,使模型容易过度拟合训练数据。针对这一问题,我们提出了位置编码扩展时间序列Transformer(PoTS-Transformer)模型。该模型创新性地结合了高维空间中的位置编码技术与低维模型架构,既能有效处理长序列,又能避免过度拟合风险。实验结果令人信服地证明了本文提出的方法有效性,为基于Transformer的时间序列预测领域提供了简洁而高效的基准实现方案。
论文地址:
https://arxiv.org/abs/2503.09791
Joni Kamarainen
喜欢就关注一下吧: